这里的堆是数据结构中的堆,不是JVM中的堆。
关键词:堆,二叉树,优先级队列,排序,topN
结构
堆的结构是完全二叉树,而且是有序的,分大顶堆和小顶堆。
完全二叉树
- 路径长度是指路径上的边数
- 结点深度是指从根结点到该结点的路径的长度
- 每一层都是满的或者最后一层不满但最后一层的叶子都是靠左放置
二叉堆
- 完全二叉树
- 每个结点大于或等于它的任意一个孩子
这里有个地方要跟BST做区别,BST的左右孩子是有大小区分的,而二叉堆中没有区分,主只要父节点比孩子结点大(大顶堆)就可以。
存储
可以将二叉堆用数组来存储。
例如如下一个二叉堆:
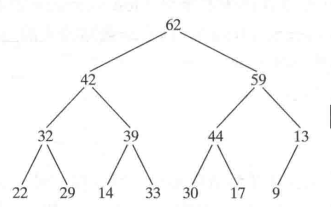
在数组中保存:{62,42,59,32,39,44,13,22,29,14,33,30,17,9}
可以看到相当是以广度优先遍历了这个二叉树,并将遍历的结点按顺序存入数组。可以从中发现一些存储的规律,对于任意一个位置_i_,他的左子结点在_2i+1_处,右子结点在_2i+2_处,父结点在_(i-1)/2_处。例如:39在数组中的下标是4,那么他的左子结点就在(2×4+1)=9处。
过程分析
我们详细看看他的 插入和删除的过程,(假设是大顶堆)
插入:元素首先放在末尾,然后与父节点比较,如果比父节点大,与父节点换位子,如此往复,直到父节点比自己大为止。
删除:移除根节点,将末尾元素拿来顶替,然后与孩子结点中最大的比较,如果比最大的孩子结点小,跟孩子结点换位子,如此往复,直到比最大的孩子结点大为止。
时间复杂度分析
O(nlogn)。
首先分析logn,同快排、归并一样,logn可以是树高、递归的栈深。
这里的n指的是用来构建堆的时间,有n个元素,那么就会有n个logn(最差情况下,每个新添的元素都会一路置换到顶部)。
应用
优先级队列
优先级队列的底层就是用堆来实现的。同时一道比较经典的算法题用优先级队列可以轻松实现:top n 问题
TOP N
给一组数据,求其中最大/小的几个数。
1 | // 求最小的n个数 |
上面用到了小顶堆,for循环中的两个判断,符合条件的放进堆中,第二个判断中,当堆中的元素个数大于要求的个数时,删除堆中的顶部元素(优先级队列的本质还是队列,进出满读FIFO)。
稍作修改,可以让上面的代码输出最大的n个数,显而易见的是,我们只需修改入队列的条件以及优先级队列的堆排序方式:
1 | // 默认大顶堆 |
大数据
当有千万级别的数据时,从中找出前若干个大(或小)的数据,虽然也是使用堆,但是多了一点选用的技巧:
- 选前K个最小的数据,使用大顶堆
- 选前K个最大的数据,使用小顶堆
两个的原理是一样的,这里我用大顶堆举例。例如,在一千万的数据中找出前100个最小的数据,遍历的同时使用大顶堆来装数据,在遍历到第101个数据的时候,与堆顶做对比,此时会有两种情况:
- 比堆顶的数字大:略过。我们要找的是前100个最小的元素
- 比堆顶的数字小:移除堆顶元素,放入第101号元素
这样一来,我们避免了对所有元素排序,核心原理就是拿栈顶元素来做临界值,时间复杂度也可以控制在O(k\n)*,其中k是前K个元素的数量,n是全部的数据量。